本文共 4303 字,大约阅读时间需要 14 分钟。
首发地址:
更多深度文章,请关注云计算频道:
关于dropout的分析,可以见博主的另外一篇文章:
1.引言
随着2012年Hiton的文章《ImageNet classification with deep convolutional neural networks》[1]的问世,掀开了学术界深度学习快速发展的序幕;而阿法狗打败世界顶级棋手李世石后,再次经过一年多的“深山老林修炼”,强化后完胜世界围棋冠军柯洁,让人们感受到了人工智能的发展速度与工业化进程的到来。目前深度学习在很多领域的都吸引众多研究者的注意,比如目标识别、语言识别、目标检测、图像分类等,深度学习在这些领域以自动提取特征的能力表现出优异的性能。
深度学习较传统网络而言,使用的是一个非常深层的神经网络,并采用大数量的数据集。因此,在这个过程中会面临一个严峻的问题——过拟合。什么是过拟合呢?打个比方,高考前各种刷题全部能做对但理解的不好,很多答案都是强行背下来的,但是一到考场,题目稍微变一点,整个人就懵了。这是因为对于机器而言,使用算法学习数据的特征时候,样本数据的特征可以分为局部特征和全局特征,全局特征就是任何你想学习那个概念所对应的数据都具备的特征,而局部特征则是你用来训练机器的样本里头的数据专有的特征。机器在学习过程中是无法区别局部特征和全局特征的,于是机器在完成学习后,除了学习到了数据的全局特征,也可能学习得到一部分局部特征,而学习的局部特征比重越多,那么新样本中不具有这些局部特征但具有所有全局特征的样本也越多,于是机器无法正确识别符合概念定义的“正确”样本的几率也会上升,也就是所谓的“泛化性”变差,这是过拟合会造成的最大问题。
那么为了避免过拟合的出现,通用的做法是在算法中使用正则化,这也是Hinton在文献[2]中提出的技巧“(dropout learning)”。“丢弃学习”包含两个步骤:在学习阶段,是以概率p忽略掉一些隐藏节点,这一操作减小了网络的大小;而在测试阶段,将学习的节点和那些没有被学习的节点求和后并乘以丢弃概率p计算得到网络的输出。我们发现可以将学习到的节点与没有学习的节点求和相乘概率p这一过程看作是集成学习。
集成学习(Ensemble Learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法,相对于单个分类器作为决策者,集成学习的方法就相当于多个决策者共同进行一项决策。可以看到,这与分而治之地把问题分解成若干个子问题,然后再想办法从个别解综合求得整体解是不同的。集成学习的处理过程是不是有点熟悉?是不是与丢弃学习类似?下面将具体分析如何将丢弃学习看成是集成学习。
2.模型
本文中使用的模型是老师-学生模型,并假设存在一个老师网络(teacher)能够使得学生网络(student)产生最优输出。下面介绍一些构造的老师及学生模型,并引入梯度下降算法。
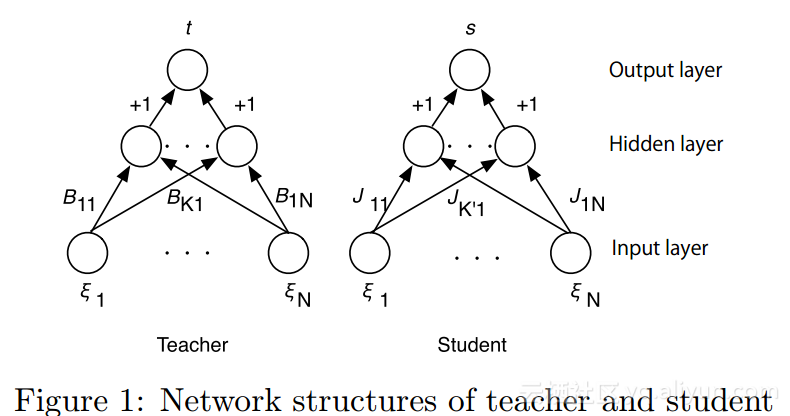
从图中可以看到,老师和学生都是一个具有N个输入节点、多个隐藏节点及一个输出节点组成的软决策机。老师是由K个隐层节点组成,而学生是由K’个隐藏节点组成,每一个隐藏节点都是一个感知机,老师的第k个隐藏权重向量用![]() 表示,学生的第k’个隐藏权重向量用
表示,学生的第k’个隐藏权重向量用![]() 表示,其中m表示学习迭代次数。在软决策机中,所有的隐藏节点到输出节点的权重固定为+1,这种网络计算得到的是隐藏层输出的多数表决结果。另外假设老师和学生的输入都是
表示,其中m表示学习迭代次数。在软决策机中,所有的隐藏节点到输出节点的权重固定为+1,这种网络计算得到的是隐藏层输出的多数表决结果。另外假设老师和学生的输入都是![]() 、老师的输出是
、老师的输出是![]()
![]() ,学生的输出是
,学生的输出是![]() 。其中g(.)表示的是隐藏节点的输出函数,
。其中g(.)表示的是隐藏节点的输出函数,![]() 是老师模型中第k个隐藏节点通过
是老师模型中第k个隐藏节点通过![]() 计算得到;同理,
计算得到;同理,![]() 是学生模型中第k’个隐藏节点通过
是学生模型中第k’个隐藏节点通过![]() 计算得到。
计算得到。
同时我们假设输入向量![]() 中的第i个元素
中的第i个元素![]() 是具有零均值和单位方差的独立随机变量,即输入的第i个元素来自于概率分布
是具有零均值和单位方差的独立随机变量,即输入的第i个元素来自于概率分布![]() ,并且由热力学极限假设可知:
,并且由热力学极限假设可知:![]() 、
、![]() ,其中<>表示求平均,||.||表示求向量的模;对于中间隐藏层而言,每一个元素Bki,k=1~K是来自于零均值和方差为1/N的概率分布。同样地,由热力学极限假设可知
,其中<>表示求平均,||.||表示求向量的模;对于中间隐藏层而言,每一个元素Bki,k=1~K是来自于零均值和方差为1/N的概率分布。同样地,由热力学极限假设可知![]()
![]() ,
,![]() ,这也意味着任意两个
,这也意味着任意两个![]() ,另外
,另外![]() 服从零均值和单位方差的高斯分布。
服从零均值和单位方差的高斯分布。
基于以上分析,我们假设每个元素![]() 来自于零均值和方差为1/N的概率分布,统计学生的第k’个隐藏权重向量得到
来自于零均值和方差为1/N的概率分布,统计学生的第k’个隐藏权重向量得到![]() 、
、![]() ,这意味着任意两个
,这意味着任意两个![]() 。学生网络的隐藏节点输出函数g(.)与老师网络一样,统计学生的第m次迭代的权重向量得到
。学生网络的隐藏节点输出函数g(.)与老师网络一样,统计学生的第m次迭代的权重向量得到![]() ,其中
,其中![]() ,
,![]() 服从零均值和方差为
服从零均值和方差为![]() 的高斯分布。
的高斯分布。
接下来,引入随机梯度下降算法(SGD),泛化误差定义为下式:
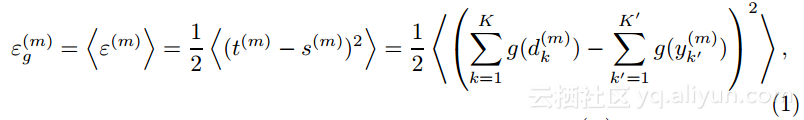
并且学生的隐藏权重向量通过下式更新
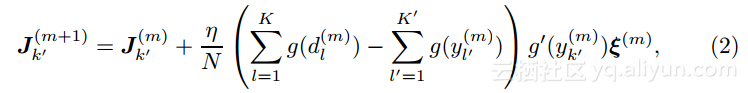
其中η是学习步长大小,g’(x)是实际隐藏节点输出函数g(x)的导数。
通过在线学习来训练网络,每次使用的是一个新输入,因此不会发生过拟合现象。为了评估丢弃学习,预先选择整个输入经常是使用的在线方式。根据经验,当输入是N维时,如果预先选定10xN的输入就会导致过拟合的现象。
3.丢弃学习和集成学习
3.1 集成学习(Ensemble Learning)
集成学习是使用许多的学习者(学生)来实现更好的性能,在集成学习中,每一个学生独立地学习老师模型,并且将每个输出平均以计算出集成输出sen。
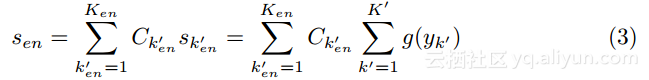
其中![]() 是平均权重,
是平均权重,![]() 是学生数量。
是学生数量。
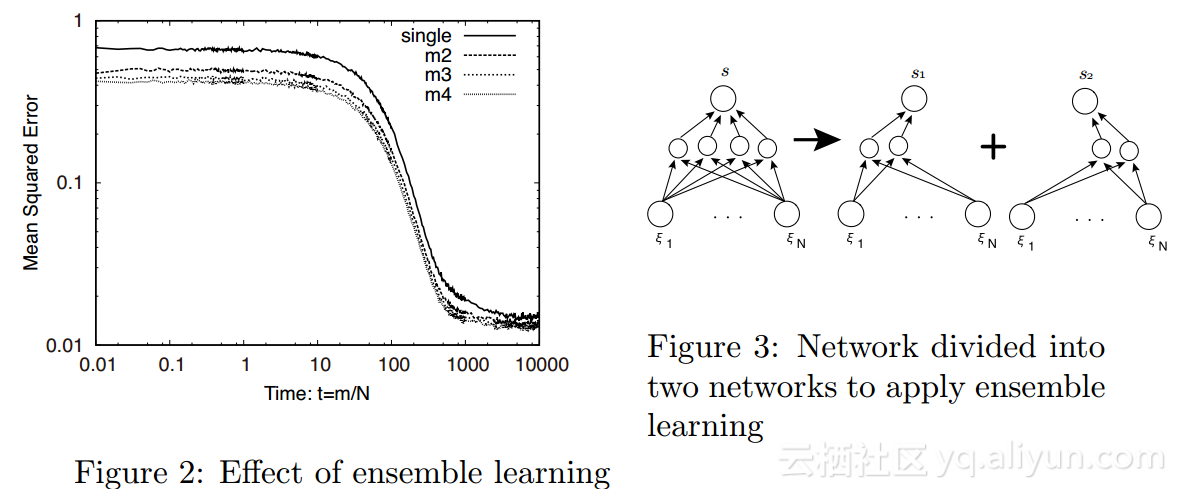
图2展示了计算机仿真的结果,老师和学生模型都包含两个隐藏节点,输出函数g(x)是误差函数![]()
![]() 。从图中可以看到,水平坐标轴是时间t=m/N,这里m是迭代次数,N是输入节点的维度,取N=10000,并且10xN输入经常被使用;纵坐标是均方误差(MSE),每个元素
。从图中可以看到,水平坐标轴是时间t=m/N,这里m是迭代次数,N是输入节点的维度,取N=10000,并且10xN输入经常被使用;纵坐标是均方误差(MSE),每个元素![]() 都是零均值单位方差的独立随机变量。图2中“single”是使用一个学生的实验结果,“m2”是同时使用两个学生的结果,同理可得,“m3”和“m4”分别是同时使用3个学生和4个学生的结果。正如图2所示,同时使用4个学生的效果要优于其他两种情况。
都是零均值单位方差的独立随机变量。图2中“single”是使用一个学生的实验结果,“m2”是同时使用两个学生的结果,同理可得,“m3”和“m4”分别是同时使用3个学生和4个学生的结果。正如图2所示,同时使用4个学生的效果要优于其他两种情况。
下面我们将修改集成学习,将学生模型(K’个隐藏节点)划分为Ken个网络,如图3所示(这里K’=4,Ken=2),划分后的网络将单独学习老师模型,并且通过将输出![]() 平均得到整体输出sen:
平均得到整体输出sen:
![]()
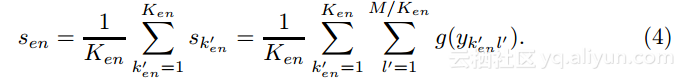
其中,![]() 是划分后的网络的输出,
是划分后的网络的输出,![]() 是第
是第![]() 个划分网络中的第l’个隐藏输出;将等式3和等式4对比来看,当
个划分网络中的第l’个隐藏输出;将等式3和等式4对比来看,当![]() 和
和![]() ,两等式相等。
,两等式相等。
3.2丢弃学习(dropout Learning)
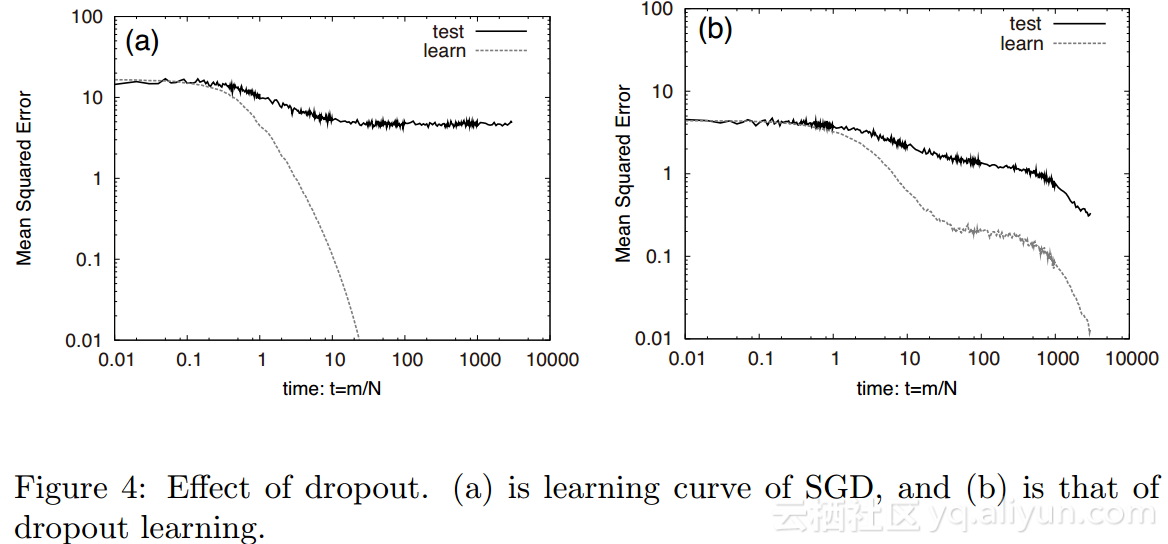
丢弃学习是在深度学习中被使用的一种技巧,以用来阻止过拟合的发生。如果发生过拟合,学习误差和测试误差将会变得不一样。图4展示了随机梯度下降(4(a))和应用了丢弃学习(4(b))的结果,二者对比可以看到,4(a)中发生了过拟合,而4(b)中没有发送过拟合。因此丢弃学习能够阻止过拟合的发生。
对于软决策机而言,丢弃学习的学习公式可以用下式表示:

其中,![]() 表示隐藏节点的集合。在学习之后,学生们的输出s(m)是通过将学习的隐藏节点输出求和后并乘以丢弃概率p得到。
表示隐藏节点的集合。在学习之后,学生们的输出s(m)是通过将学习的隐藏节点输出求和后并乘以丢弃概率p得到。
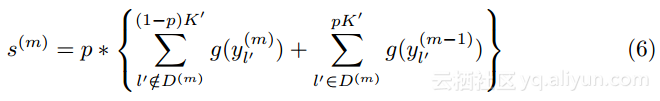
当丢弃概率p=0.5时,上式可以看成是一个学习网络(第一项)与不学习网络(第二项)的集成。当![]() 和
和![]() 时,等式6对应于等式4。然而,
时,等式6对应于等式4。然而,![]() 在每次迭代学习中是随机挑选的,因此,丢弃学习可以看成是在每次迭代中不同隐藏节点集合的集成学习表现。
在每次迭代学习中是随机挑选的,因此,丢弃学习可以看成是在每次迭代中不同隐藏节点集合的集成学习表现。
4.结果
4.1 将丢弃学习与集成学习作对比
在这一部分,我们将误差函数![]() 用作输出函数g(x),比较丢弃学习与集成学习。针对于集成学习,将隐藏节点设置为50;针对于丢弃学习,将隐藏节点设置为100,并设置丢弃概率p为0.5,即丢弃学习将选择50个隐藏节点作为
用作输出函数g(x),比较丢弃学习与集成学习。针对于集成学习,将隐藏节点设置为50;针对于丢弃学习,将隐藏节点设置为100,并设置丢弃概率p为0.5,即丢弃学习将选择50个隐藏节点作为![]() 及剩余的50个节点不被选择;输入维度N=1000,学习率η=0.01。仿真结果如图5所示,其中横纵坐标跟图4的含义相同,在图5(a)中,“single”表示使用50个隐藏节点的软决策机的结果,“ensemble”表示使用集成学习的结果;图5(b)中,“test”表示测试数据的MSE,“learn”表示学习数据的MSE。
及剩余的50个节点不被选择;输入维度N=1000,学习率η=0.01。仿真结果如图5所示,其中横纵坐标跟图4的含义相同,在图5(a)中,“single”表示使用50个隐藏节点的软决策机的结果,“ensemble”表示使用集成学习的结果;图5(b)中,“test”表示测试数据的MSE,“learn”表示学习数据的MSE。
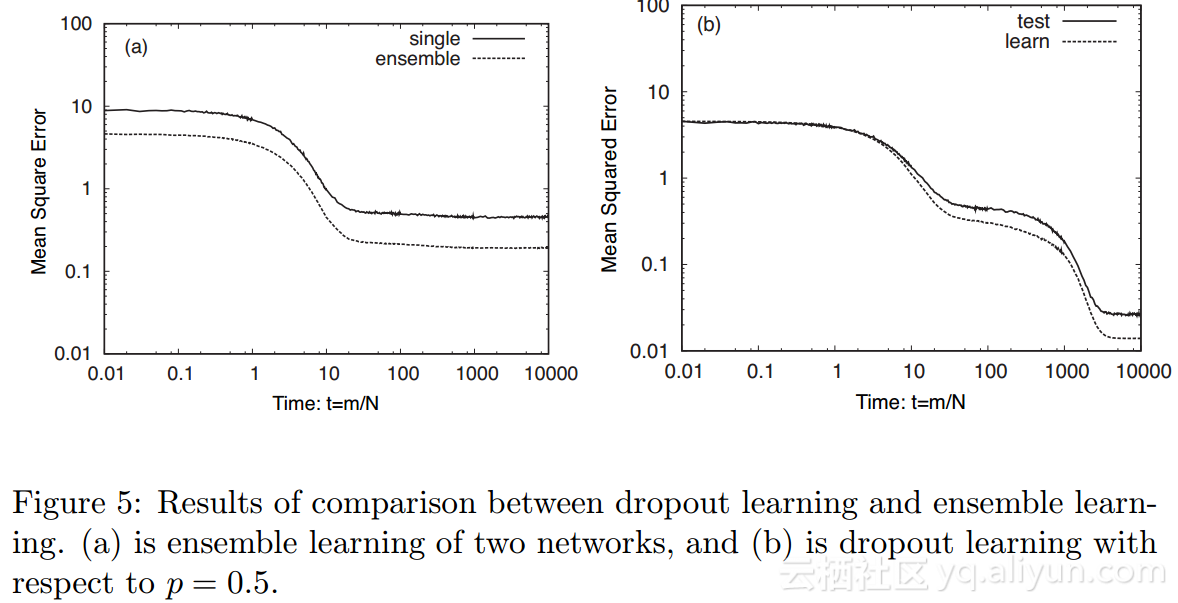
正如图5(a)所示,集成学习实现的MSE要比单独一个网络的MSE更小,然而,丢弃学习实现的MSE比集成学习的MSE更小。因此,在每次迭代中,集成学习使用不同的隐藏节点集合比使用相同隐藏节点集合的性能更好。
4.2 将丢弃学习与带有L2范数的随机梯度下降法作对比
带有L2范数的随机梯度下降法的学习等式可以用下式表示:
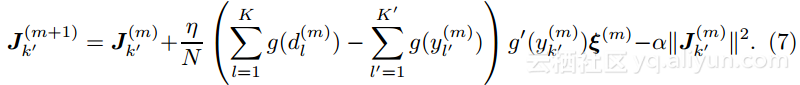
其中,α是L2范数的系数,也称为惩罚系数。
图6展示了带有L2范数的随机梯度下降算法的结果(实验条件与图5相同):
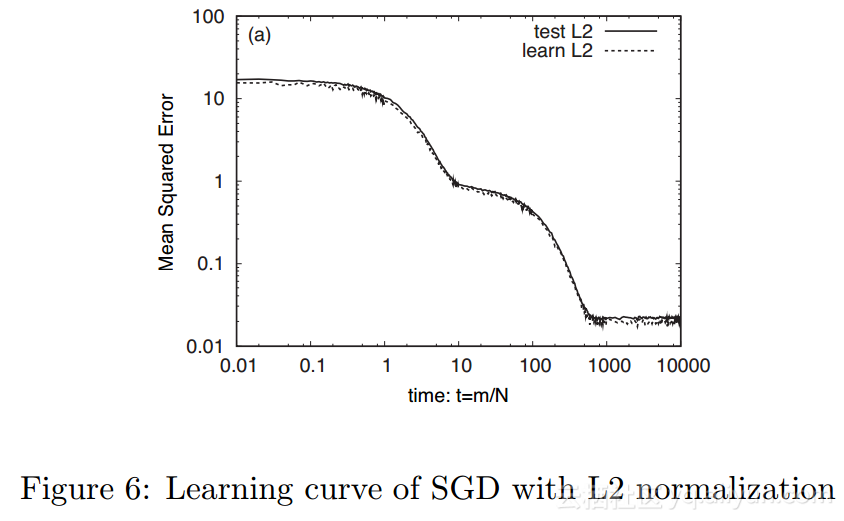
对比图6和图5(b)可以看到,丢弃学习与带有L2范数的随机梯度下降算法的结果几乎相同。因此,丢弃学习的正则化效果与L2范数的相同。注意到,L2范数的随机梯度下降算法中,我们在每次尝试中必须选择α参数,而丢弃学习不需要调节参数。
5.结论
本文分析了可以将丢弃学习当作是集成学习。在集成学习中,可以将一个网络划分成若干个子网络,并且单独训练每个子网络。在训练学习后,将每个子网络的输出进行平均得到集成输出。另外,我们展示了丢弃学习可以看成是在每次迭代中不同隐藏节点集合的集成学习表现,同时也展示了丢弃学习有着与L2正则化一样的效果。后续将分析带有ReLU激活函数的丢弃学习的性能。
参考文献:
[1]Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
[2]Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. Computer Science, 2012, 3(4):pages. 212-223.
作者信息
,东京都理工大学教授,研究方向是机器学习与在线学习。
本文由北邮老师推荐,组织翻译。
文章原标题《Analysis of dropout learning regarded as ensemble learning》,作者:Kazuyuki Hara,译者:海棠,审阅:
文章为简译,更为详细的内容,请查看
翻译者: 海棠
Email:duanzhch@tju.edu.cn
微信公众号:AI科技时讯

转载地址:http://ludux.baihongyu.com/